
Tech
India’s Sarvam AI Claims Benchmark Edge Over Gemini and ChatGPT in Indic Vision Intelligence
From 22-language OCR to multimodal document understanding, Bengaluru-based Sarvam AI positions itself as India’s sovereign answer to global AI giants.

In the middle of Bengaluru’s dense tech ecosystem, Sarvam AI is attempting something ambitious and distinctly Indian. The startup claims that its latest models, Sarvam Vision and Bulbul V3, have outperformed global AI systems such as Google Gemini and OpenAI’s ChatGPT on India-specific tasks. The focus is not on flashy chatbot replies. It is on document intelligence, multilingual OCR, and visual-language understanding built around India’s real-world data complexity. This is not being framed as a rivalry for headlines. It is being presented as a shift toward sovereign AI, where India builds foundational systems aligned with its linguistic and institutional needs rather than adapting global-first models.
What Is Sarvam AI?
Sarvam AI is a Bengaluru-based artificial intelligence startup building foundational AI infrastructure for India. The company describes its mission as creating sovereign AI systems that are accessible, reliable, and controlled within India.
Recently, co-founder Pratyush Kumar shared details of Sarvam Vision on X, introducing it as a state-space-based 3-billion-parameter vision-language model. The model extends beyond text and voice into visual understanding, targeting document digitisation challenges across English and 22 official Indian languages.
What Makes Sarvam Vision Different?
Sarvam Vision is designed specifically for document intelligence. India operates through vast archives of physical documents, scanned records, handwritten files, government paperwork, court records, financial forms, historic manuscripts, and regional newspapers. Many of these exist in scripts that global AI systems treat as low-resource or secondary.
Sarvam Vision has been trained on high-quality datasets covering all 22 official Indian languages. These include financial documents, literature, newspapers, historic texts, and diverse scanned layouts. The objective is not just translation but contextual understanding and structured extraction.
Key capabilities include:
- Multimodal vision-language understanding
- Interprets images and text together for tasks such as captioning, table reading, and layout analysis.
- Document understanding in Indian languages
- High-accuracy OCR and knowledge extraction for regional scripts and complex scanned documents.
- Charts and data interpretation
- Goes beyond text extraction to interpret tables, graphs, and visual data elements.
- Multilingual visual comprehension
- Handles mixed-language documents where English and regional scripts appear together.
- Production-ready APIs
- Document Intelligence APIs are free to use through February 2026 for experimentation.
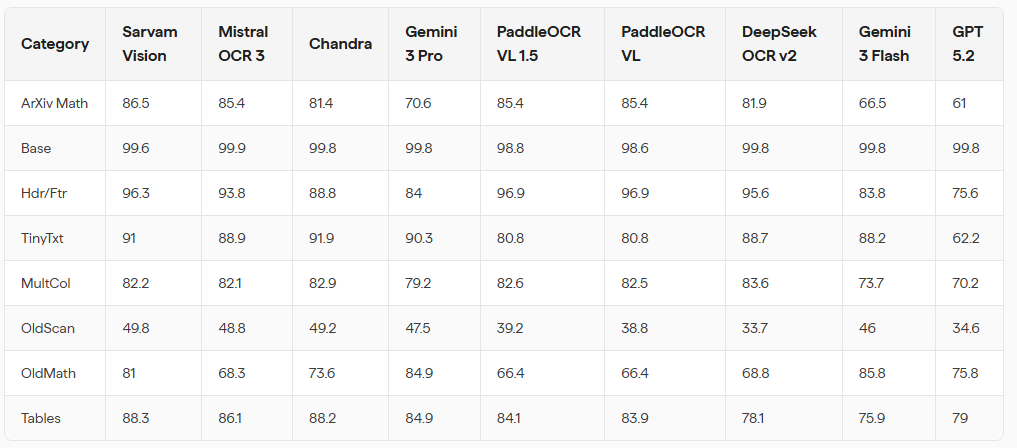
Benchmark Numbers That Sparked Attention
Sarvam AI reports that Sarvam Vision achieved:
- 84.3 percent accuracy on olmOCR-Bench, surpassing Gemini 3 Pro and DeepSeek OCR v2
- 93.28 percent accuracy on OmniDocBench v1.5
In addition to competing on global English benchmarks, the company introduced the Sarvam Indic OCR Bench, specifically designed to evaluate performance in Indian languages.
The emphasis is on practical execution. Complex layouts. Scanned pages. Regional scripts. Mixed documents. Real files, not ideal datasets.
How It Differs From Gemini and ChatGPT
Global models like Gemini and ChatGPT are primarily optimised for English and high-resource languages. Indic scripts often receive secondary optimisation.
Sarvam AI flips that hierarchy. It trains directly on Indian language datasets across 22 official languages, prioritising regional accuracy rather than treating them as add-ons.
While other models may extract text from images, Sarvam claims stronger performance in understanding visual structure, contextual meaning, and multilingual complexity within a single document.
The positioning is clear: build AI for India first, benchmark globally second.
Why Sovereign AI Matters for India
Sarvam AI describes itself as building sovereign AI. The term reflects more than localisation. It signals:
- Data control within India
- Infrastructure tailored to Indian governance and institutions
- Multilingual inclusion
- Reduced dependency on imported AI systems
Industries such as healthcare, education, banking, insurance, and public administration rely heavily on document workflows in multiple languages. Accurate Indic OCR and multimodal document interpretation could significantly improve digitisation, compliance, and analytics.
Execution Over Hype
For February 2026, Sarvam has opened its Document Intelligence API for free experimentation. This move suggests a strategy focused on developer adoption and enterprise integration rather than promotional noise.
Bulbul V3 complements the ecosystem, extending Sarvam’s presence in text and voice capabilities. Together, these releases indicate a broader attempt to build foundational AI components rather than isolated features.
India’s AI Moment?
Sarvam AI’s claims are bold. If sustained under broader testing and enterprise deployment, they could mark a turning point in India’s AI narrative.
Not as a consumer adapting global systems, but as a builder of models trained on its own languages, archives, and institutional realities.
In a global AI race dominated by scale, Sarvam is betting that India’s scale lies in specificity.

These Indian Women Runners Show Life Doesn’t Stop And Neither Do They

Siddhesh Lokare’s Workshop Is Teaching Creators What Actually Matters Beyond Virality

Ranveer Allahbadia and Kunal Kamra Clash Again

Aakanksha Monga Launches ‘Creator Takeoff’ to Help Aspiring Travel Creators

Varsha Shekhawat: From 55 Stitches to Self-Made Strength, A Story That Refuses Sympathy

What Actually Drives Reels’ Engagement? New Data Reveals What Works in 2026

Should Social Media Be Banned for Kids Under 16? Pinterest CEO Sparks Global Debate

Why Social Media Is the Biggest Growth Engine for Small Businesses in 2026

India’s Creator Economy Is Booming But Broken Payments Are Becoming Its Biggest Bottleneck

Creators Decoding Eid Fits and Relatable Content You Can’t Afford To Miss

Food Pharmer’s Cannes Look That Never Walked

Parul Gulati Wears Nish Hair on the Cannes 2025 Red Carpet

Nancy Tyagi’s 700-Hour DIY Gown Turns Heads at Cannes 2025

Navya Nanda’s IIM Ahmedabad Triumph: From Controversy to Campus Joy

Influencer Kareema’s Heartwarming Journey with Suki

Prajakta Koli and Vrishank Khanal’s Wedding

Prajakta Koli’s Haldi and Cocktail Celebrations

Prajakta Koli and Vrishank Khanal’s Pre-Wedding Celebrations

Prajakta Koli x Vrishank Khanal Magical Mehendi

Milind Soman & Ankita’s Maha Kumbh 2025 Experience

Update: UK07 Rider Breaks Silence in an Emotional ‘Last Vlog’, Blames Family Conflict for Mental Distress
These Indian Women Runners Show Life Doesn’t Stop And Neither Do They

Maharashtra Influencer Arun Tupe Found Dead on March 10 at Home in Chhatrapati Sambhajinagar

How Niranjan Mondal Is Turning Bengali Reels into Mainstream Storytelling

Neel Salekar, Yashashree Rao Team Up for Marathi Music Video ‘Ved Lavla’

The Real Story of Arun Kumar, India’s Internet ‘Laughing Meme Boy’
Creators Decoding Eid Fits and Relatable Content You Can’t Afford To Miss

Ugadi & Gudi Padwa 2026: Creators Bring Festive Vibes to Life

Ashish Chanchlani Is India’s Sole Creator for Global ‘Spider-Man: Brand New Day’ Campaign
